아키텍쳐 그리기
주어진 요구사항을 반영하여 진행할 프로젝트에 대한 아키텍쳐를 그렸다.

해당 아키텍쳐는 하루종일 완성한 4.0ver. 이다. 우리는 전날에 전달받은 요구사항의 목적을 구체화했고, 그것을 달성하기 위해 요구사항을 잘게 쪼개어 이해했다. 그 후 요구사항이 분명하지 않아서 더 설명이 필요하거나 구현에 어려움이 있을 것 같은 부분에 대한 질문 사항을 오전에 정리했다.
소비자가 예약을 진행할 때, 예약 정보를 RDS에 저장한다.
// 어떤 형태로 데이터가 오는가 → 어떤 데이터가 오든 처리할 수 있어야 한다.
// rds를 어디에 연결할 것인가 → ElastiCache와 연결한다.
드라이버가 예약을 인지할 수 있도록 해당 메시지를 알림 서버에 전달한다.
// 어떻게 알림서버를 구성할 것인가 → 가용성과 확장성, 자동화를 위하여 ECS를 사용하고, SQS로 느슨하게 결합한다.
// 알림 서버에 어떤 메시지를 줄 것인가 → {”소비자”: “예약됨!”}
예약 정보를 다루는 서버는 추가 될 트래픽에 대한 확장성이 보장되어야한다.
// 오토스케일링+ec2
// 서버는 뭘로써야하는지 express or fastify 혹은 다른 기술적 제약이 있는가
알림 서버는 추가 될 트래픽에 대한 확장성이 보장되어야한다.
// 오토스케일링+ecs
// express or fastify 혹은 다른 기술적 제약이 있는가
// ecs 조사하기
// 서비스가 두 개, 서버도 두 개, 도커를 적용?
데이터 내구성을 보장하기 위해 RDS는 복제본이 만들어져야 한다.
// 어디에? 얼마나? 어떻게? → Multi AZ에 트래픽에 따라 자동적으로 확장되도록 한다.
빠른 예약 정보 검색을 위해 쿼리결과는 ElastiCache를 통해 캐싱이 되어야 한다.
// 어떤 쿼리? 어느정도로?
// 캐싱 방식에 따른 성능 차이가 있는가
⇒ ec2에서 나온 데이터를 s3에 넣자, 람다를 통해 전처리로 elasticsearch로 넘기자
예약 내역이 담긴 메시지 누적은 Elasticsearch를 통해 제공된다.
// elasticsearch는 어떻게 로그를 제공하는가 → 고려하지 않아도 무방함.
누적된 로그는 예약 정보를 담는 rds와는 별도의 db에 저장된다.
// 가공된 데이터는 어디로 가는가? → Elasticsearch가 별로의 db 역할을 한다. 또한 데이터 전처리도 필요없다.
예약 서비스와 조회 서비스는 별도로 관리되는 서비스이다.
// 각 서비스가 마이크로서비스 인가 → 맞다.
// 느슨한 연결은 어떻게 하는가? sqs 뿐인가
// 각각 오케스트레이션 해야하는가
오전에 요구사항을 명시적으로 모든 팀원이 인지하고, 서비스별로 역할을 분담하여 각 서비스에 대한 이해를 목적으로 시간을 보냈다.
오후에 팀 얼라인 시간을 통해 각자가 학습한 것들을 공유하여 나름대로 답을 냈고, 부족한 부분은 CTO에게 면담을 통해 알아가기로 했다.
GitHub project를 사용하여 kanban 보드를 만들고 서로의 상황을 공유했다.

나의 역할
나는 ElasticSearch, ElastiCache에 대한 기술조사를 진행했다. 4가지 기준을 정해 너무 깊게, 너무 얕게 조사하지 않도록 가이드라인을 설정했다. 다음과 같다.
- 왜 해당 기술스택을 써야하나?(장, 단점을 기준으로)
- 어떻게 작동하나?(데이터 흐름을 기준으로)
- 다른 대체 방안은 없는가?
- 비용은 어떤가?
내가 맡은 2가지 기술은 모든 팀원이 처음 접하는 것이었으므로, 잘 이해가 되게 핵심만 알아봐서 팀 얼라인 시간에 공유를 성공적으로 했다.
ElasticSearch
이해하기 어려웠다. JSON 형태로 모든 로그를 수집하여 메시지 누적을 하는 것이 우리팀의 요구사항이었다. 당연히 나는 어떤 메시지가 누적되고, 누적된 메시지를 활용할 수 있는 방안까지 알아봐야한다고 생각했다. 예를들어, 고객들이 예약을 취소하거나 예약을 성공한 로그들을 모아, Query문을 통해 전체 예약현황을 따로 DB를 거치지 않고 빠르게 조회할 수 있는 기능을 생각했었다.
그래서 CTO에게 요구사항에 대한 이해가 맞는지 확인 요청을 하였다. 대답은 모든 로그를 JSON 형태로 받아 ElasticSearch라는 일종의 DB에 누적하여 저장하는 것까지가 우리팀의 요구사항이라고 전달받았다. 그 데이터를 Query하고 어떻게 사용하여 비즈니스 로직을 끌어낼지는 빅데이터 분석팀이 해야할 일이라는 것이다.
면담으로 인해 요구사항을 더욱 잘게 쪼개 우리 팀이 고민해야할 일이 명확해졌다.
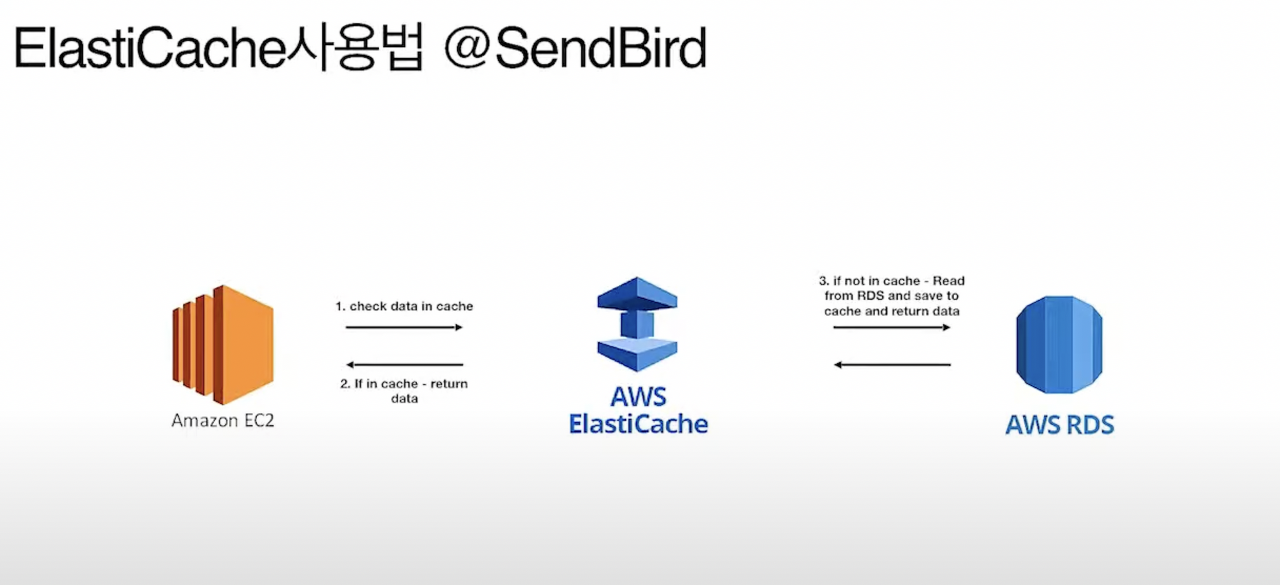
ElastiCache
이것은 데이터 조회를 빠르게 하기 위한 캐싱전략으로 일전에 nginx로 프록시서버를 구성했던 경험이 있었다. 그것과 마찬가지로 DB에 굳이 들리지 않고 빠르게 캐싱된 데이터를 조회하여 사용자 경험을 높이고, DB의 부하를 줄이는 목적이다. 이것은 간단한 아키텍쳐 그림으로 팀원들이 모두 이해했다. 이제 중요한 것은 구현방법에 대한 논의이다.
좋았던 점
- 전체 아키텍쳐를 그리기는 막막하고 어려움이 있었지만, 세부적으로 역할을 나눠 이해하니 생각보다 쉽게 구성할 수 있었다.
- 각 팀원의 역할을 명확하게 나누고, 조사에 대한 최소, 최대 요구사항을 확실하게 정하니 효율적으로 팀 얼라인을 할 수 있었다.
- Kanban 보드를 사용하여 팀원의 진행사항을 확인할 수 있고, 정리된 자료 또한 쉽게 조회가 가능하였다.
아쉬웠던 점
- 개념과 아키텍쳐 전반에 대한 이해에 앞서 컨셉증명을 먼저하여, 코드가 작동되는 방식을 봐야만 이해가 빠른 팀원이 있었다. 나의 입장에서는 먼저 전체적인 그림을 그려보고 작업을 하는 스타일이지만, 그렇지 않은 사람도 있었는데 그렇다고 강요를 할 수는 없었다.
'회고록' 카테고리의 다른 글
| [회고]Final Project Day5 (0) | 2022.05.25 |
|---|---|
| [회고]Final Project Day4 (0) | 2022.05.23 |
| [회고]Final Project Day2 (0) | 2022.05.18 |
| [회고]세번째 project를 진행하고 (0) | 2022.05.08 |
| [프로젝트 회고]WAS로 투표 서비스 만들기! (1) | 2022.03.09 |

